语音识别技术二
语音模式匹配
模式匹配即解码过程。它对经过处理的声音信号与已有的语音模型库进行匹配以达到识别的目的。经过特征识别,我们已经得到了描述声音信息内容特征的向量。接下来的解码过程 就是在给定语音模型的情况下,找到最可能对应的发音的过程。语音识别全过程如下图所示。
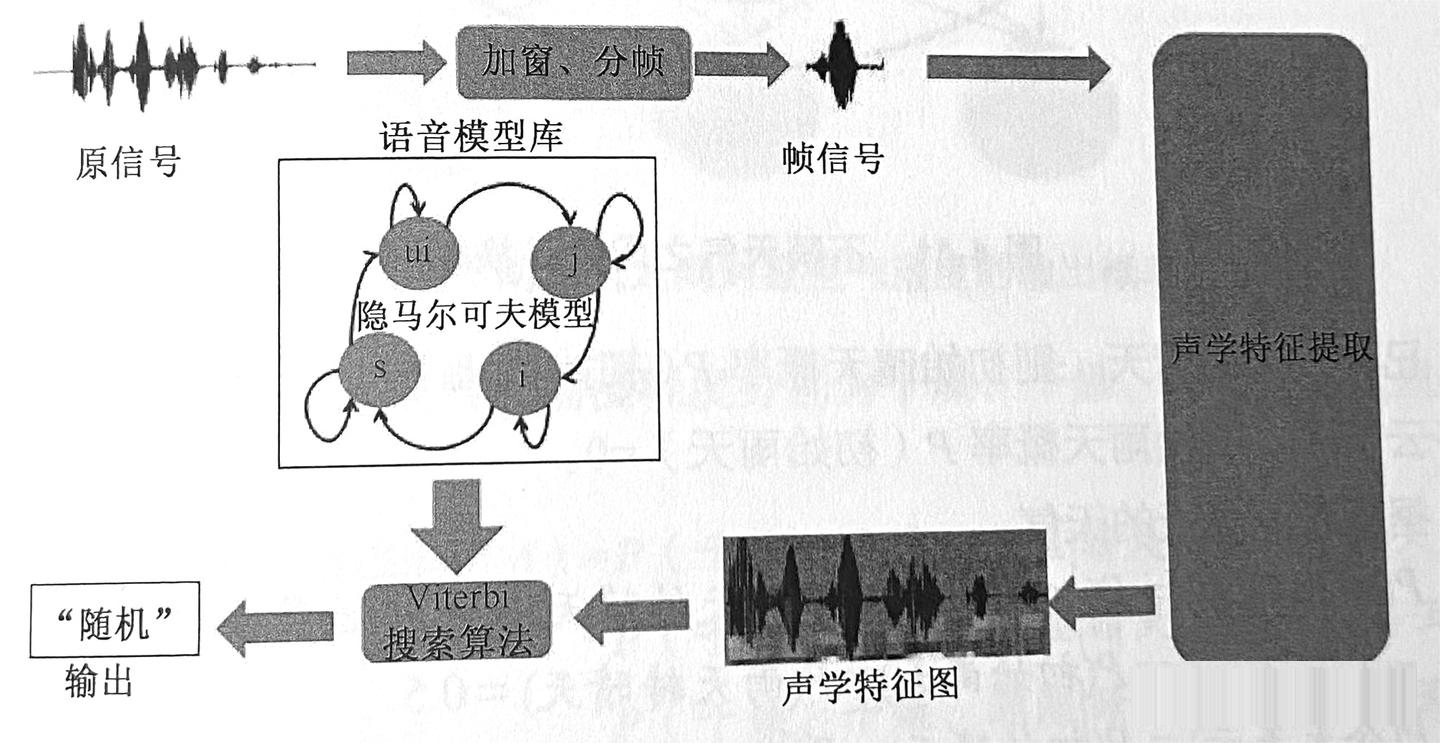
到目前为止,语音识别的技术都没有脱离隐马尔可夫模型框架。可见隐马尔可夫模型在语音识别中的重要性。为了透彻地阐述隐马尔可夫模型,让我们先来了解一下马尔可夫模型。
◆ 1)马尔可夫模型
为加深理解,以预测天气为例。假设每天天气只有三种状态:晴天、雨天、多云。若第一天为晴天,则第二天也为晴天的概率为0.5,为多云的概率为0.375,为雨天的概率为0.125。
假设第一个观察天(即昨天)为晴天,由此预测今天的天气情况。
至此,建立了一个一阶马尔可夫模型,它包含三个状态(晴天、多云、雨天)、各个状态之间的转换概率。
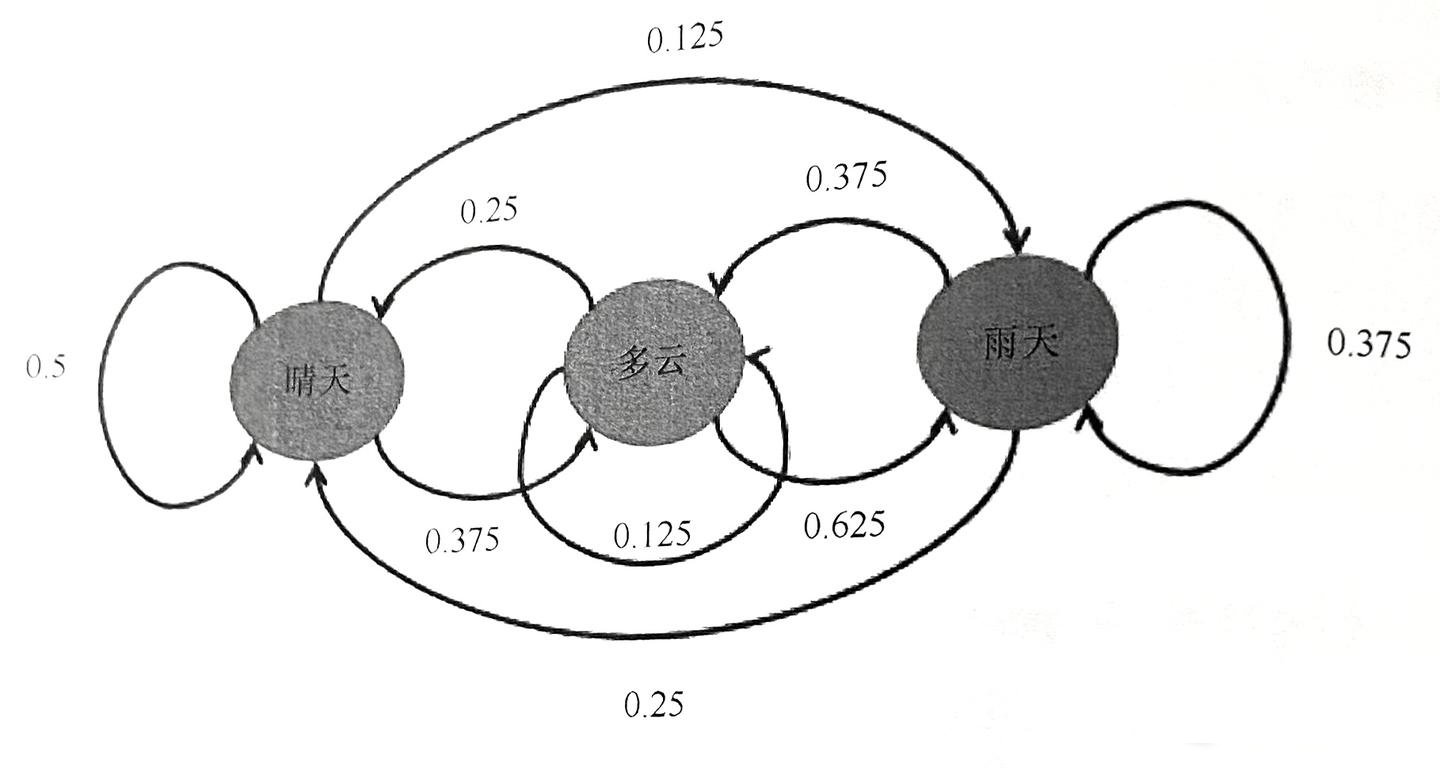
已知昨天为晴天,则初始晴天概率P(初始晴天)=1,初始多云概率P(初始多云)=0,初始雨天概率P(初始雨天)=0。
据此预测今天的天气:
P(今天晴天)=P(初始晴天)×P(晴天转晴天)+P(初始多云)×P(多云转晴天)+P(初始雨天)×P(雨天转晴天)=0.5
P(今天多云)=P(初始晴天)×P(晴天转多云)+P(初始多云)×P(多云转多云)+P(初始雨天)×P(雨天转多云)=0.375
P(今天雨天)=P(初始晴天)×P(晴天转雨天)+P(初始多云)×P(多云转雨天)+P(初始雨天)×P(雨天转雨天)=0.125
由此可知,今天为晴天的概率最大。
已知今天的天气概率情况,可据此预测明天的天气情况:
P(明天晴天)=P(今天晴天)×P(晴天转晴天)+P(今天多云)×P(多云转晴天)+P(今天雨天)×P(雨天转晴天)=0.375
P(明天雨天)=P(今天晴天)×P(晴天转雨天)+P(今天多云)×P(多云转雨天)-P(今天雨天)×P(雨天转雨天)=0.34375
p明天多云)= P(今天晴天) xP(晴天转多云)+ P(今天多云) XP(多云转多云)+) xPP(今天雨天) xP(雨天转多云)=0.28125
◆ 2)隐马尔可夫模型
在隐马尔可夫模型中,三个必备要素分别为初始概率、转换概率、输出概率。其中,初始概率和转换概率的含义与马尔可夫模型相同,输出概率是指状杰值映射到对应观测值的概率。
例如,若当前的天气情况不能直接获得,只能通过测量空气湿度间接获得。同样以天气预测为例,不同天气之间对应空气湿度的输出概率如下图所示。
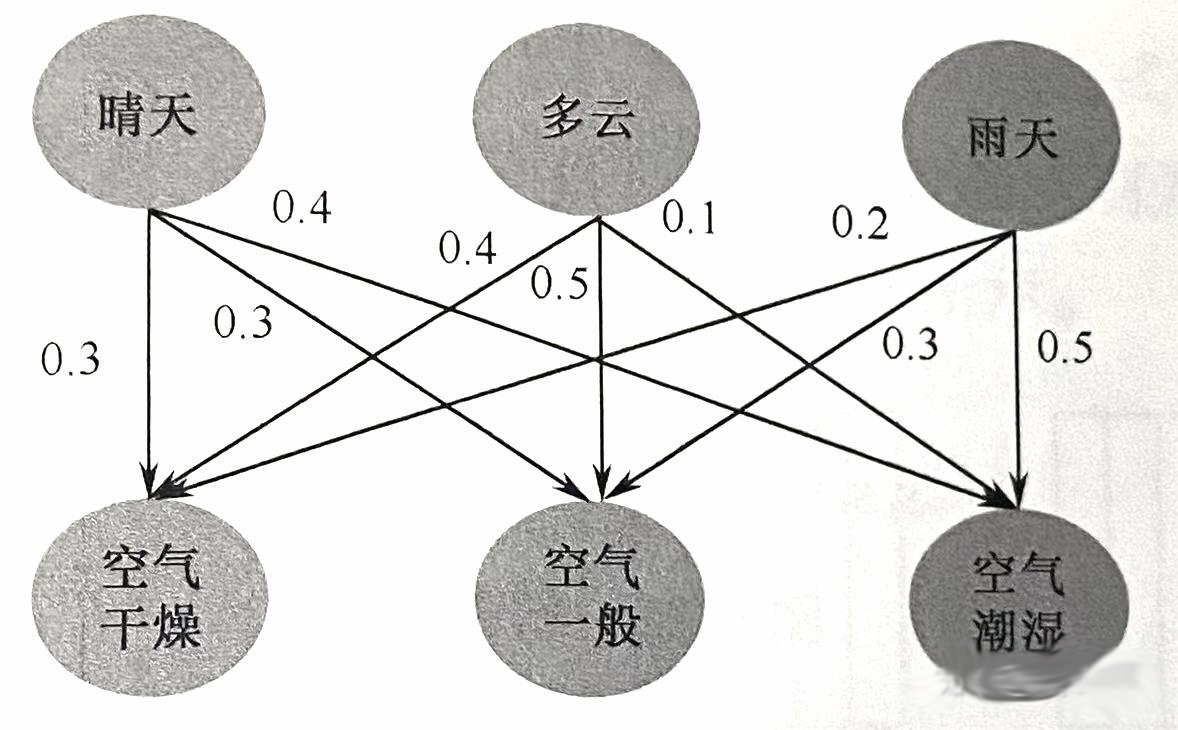
若观测到连续三天空气的潮湿程度分别为干燥、干燥、潮湿,则这里的隐马尔可夫链为:
P(干燥、干燥、潮湿|HMM)=P(干燥、干燥、潮湿晴天、晴天、晴天)+P(干燥、干燥、潮湿|晴天、晴天、多云)+
P(干燥、干燥、潮湿|晴天、晴天、雨天)+P(干燥、干燥、潮湿|晴天、多云、晴天)+…+P(干燥、干燥、潮湿|雨天、雨天、雨天)
采用穷举的办法可以找到概率最大的天气排序情况。这种由观测值推知状态值的方法就是隐马尔可夫模型。它可以用来描述含有隐含位置参数的马尔可夫过程。
以中文为例。中文的发音由声母、韵母和整体认读音节组成。因此,可将每个声母、韵母、整体认读音节称作音素。每个音素都有一定的发音规律,可以将这个发音经过特征提取后编算成计算机
可存储的声学特征并作为已知的语音模型库,以方便后续的模式匹配。
除了存储音素,语音模型库还存储了大量单字、单词、成语等语句元素所对应的语音输出概率。例如,当接收到语音信号“sui ji”时,这个信号识别为“随即”二字的概率为0.3,识别为“随机”
二字的概率为0.5。这类似隐马尔可夫模型中状态值映射到观测值的输出概率。
在完成特征提取后,就可以对未知语音帧序列进行识别了。完成模式匹配识别有以下两个步骤。
(1)使用隐马尔可夫模型构建一个状态量足够多的状态网络。状态网络的搭建由单词级别的网络展开成音素网络,再展开成状态网络。状态路径如下图所示。
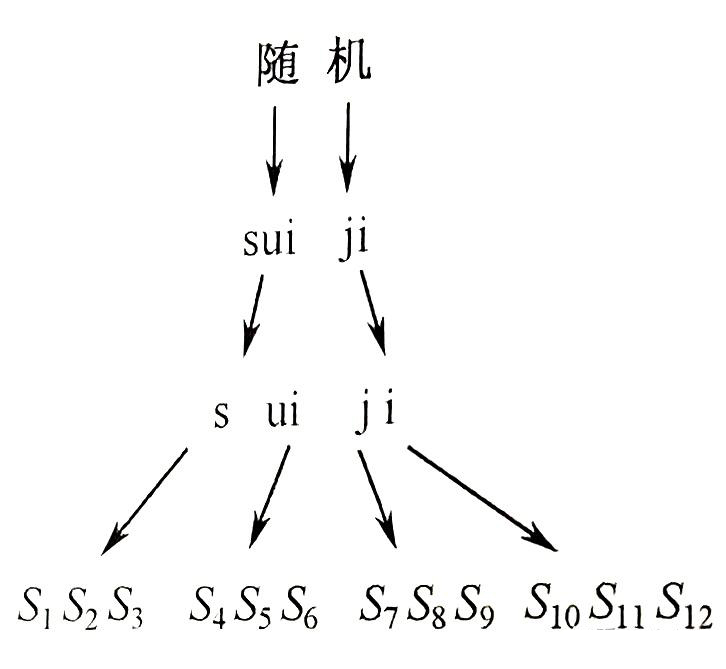
在上图中,以中文单词“随机”为例,将其拆分为音素“s”“ui”“j”“i”,并由此生成对应的状态路径S₁→S₂→S₃→S₄→Ss→S₆→S₇→Sg→S₉→S₁o→S₁→S12。
(2)从状态网络中寻找与声音最匹配的路径,即在所有可能的路径中选择一条概率最大的路径作为识别结果。这个要求可由相应的搜索算法(如Viterbi算法)满足。
由于语速不同,每个音素的持续帧数也不相同,所以可能出现一帧或几帧属于一个音素的情况,因此可将音素细分为更小的单位——状态。在隐马尔可夫模型中,状态是隐变量,语音是观测值。
通过预处理、特征提取,我们将语音信号进行了分帧,并且得到了用于描述每帧语音信号声学特征的多维向量,在隐马尔可夫模型中,这个过程的最终结果是获得观测值。
此后,将之前分割的每帧语音片段的声学特征与语音模型库中已知音素的状态的声学特征进行对比,得到当前观测值对应隐变量的输出概率,如下图所示。
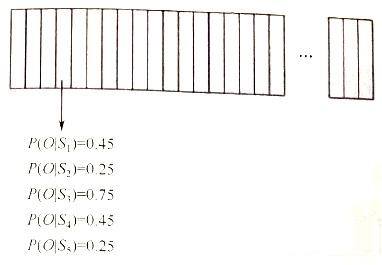
在上图中,每个小竖条代表一帧。经过条件概论公式计算,我们发现图中箭头所指向的帧在状态S₃上的概率最大,则将该帧识别为状态s₃。依此类推,识别每帧信号的状态。状态组成音素如下图所示:
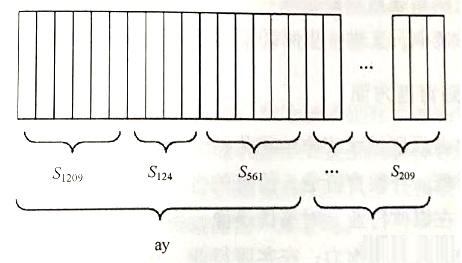
通过计算概率最大的隐马尔可夫链,可以判定当前一帧或几帧最大概率属于哪个状态,再将得到的状态凑成一个音素。
若干帧语音识别为一个状态(如上图中的Sizw状态、Siz₄状态),每三个状态组合成一个音素(如上图中的“ay”音素),若干个音素组合成一个单词。由此可见,只要知道每帧语音所对应的状态,即可得到语音识别结果。